


























1. Introduction
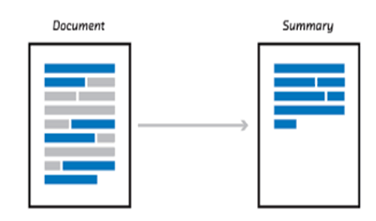
Text Summarization is a subtask of Natural Language Processing (NLP) to generate a short text but contains main ideas of a reference document. It maybe an impossible mission but thanks to the development of technology, nowadays we can create a model to generate from many texts that convey relevant information to a shorter form.
We all interact with applications which uses text summarization. Many of those applications are for the platform which publishes articles on news, politics, entertainment, … With our busy life, we prefer to read the summary of those papers, articles more than reading entire of it. Instead of reading all the article, read a summary will give you a brief about the story and save your time to select suitable articles. Otherwise, it can utilize in order to specify the most important topics of document(s). For examples, when summarizing blogs, there are discussions or comments coming after the blogs post that are good resources of information to determine which parts of the blog are critical and interesting.
There are many reasons why Automatic Text Summarization is useful:
1. Summaries reduce reading time.
2. When researching documents, summaries make the selection process easier.
3. Automatic summarization improves the effectiveness of indexing.
4. Automatic summarization algorithms are less biased than human summarizers.
5. Personalized summaries are useful in question-answering systems as they provide personalized information.
6. Using automatic or semi-automatic summarization systems enables commercial abstract services to increase the number of text documents they are able to process.
You might also interest in: Analytics to Drive Sustainability in Competitive Advantages
2. Two main approaches to text summarization
- Extraction-based summarization
This approach selects the main passages to create a summary. It will weight the important part of documents and rank them based on importance and similarity among each other.
Input document → sentences similarity → weight sentences → select sentences with higher rank.
The extractive text summarization technique involves pulling key phrases from the source document and combining them to make a summary.
- Abstraction-based summarization
Abstractive methods select words based on semantic understanding, even those words did not appear in the source documents. When abstraction is applied for text summarization in deep learning problems, it can overcome the grammar inconsistencies of the extractive method.
Input document → sentences similarity → weight sentences → select sentences with higher rank.
Therefore, abstraction performs better than extraction. However, the text summarization algorithms required to do abstraction are more difficult to develop and that’s why the use of extraction is still popular.
Other articles: The Supply Chain Sector: How AI has Penetrated into This Emerging Market?
3. Extraction-based approach
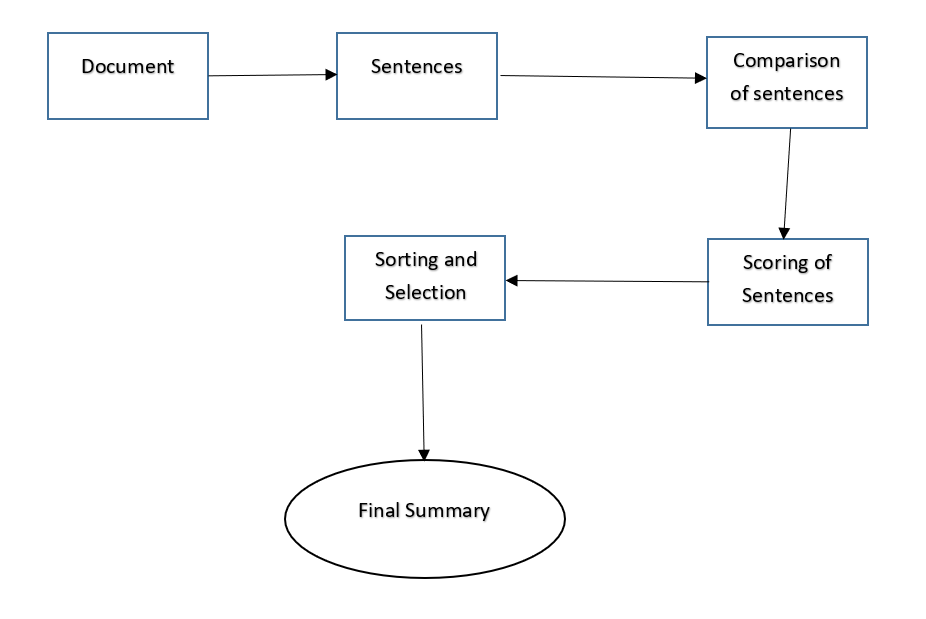
Typically, here is how using the extraction-based approach to summarize texts can work:
- Introduce a method to extract the merited key phrases from the source document. For example, you can use part-of-speech tagging, words sequences, or other linguistic patterns to identify the key phrases.
- Gather text documents with positively-labeled key phrases. The key phrases should be compatible to the stipulated extraction technique. To increase accuracy, you can also create negatively-labeled keyphrases.
- Train a binary machine learning classifier to make the text summarization. Some of the features you can use include:
- Length of the key phrase
- Frequency of the key phrase
- The most recurring word in the key phrase
- Number of characters in the key phrase
- Finally, in the test phrase, create all the key phrase words and sentences and carry out classification for them.
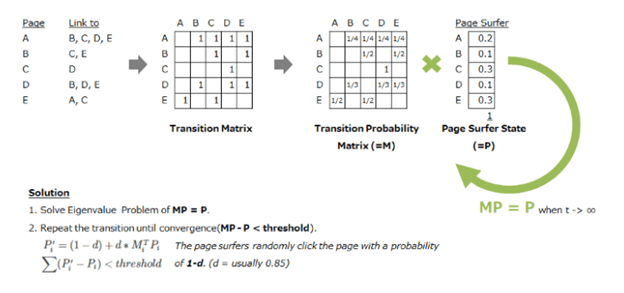
3.1. TextRank Algorithm
TextRank algorithm is a basic algorithm used in machine learning to summarized document. TextRank is an extractive and unsupervised text summarization technique. TextRank does not rely on any previous training data and can work with any arbitrary piece of text
- Similarity between any two sentences is used as an equivalent to the document transition probability
- The similarity scores are stored in a square matrix, similar to the matrix M used for PageRank. This matrix is a similarity matrix
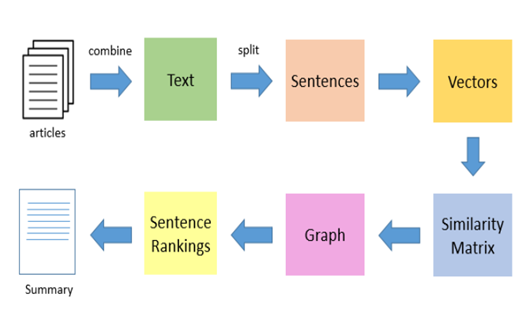
- First step is combine all the text in the documents to a document.
- Then, split this document into individual sentences.
- In the next step, we will find vector representation (words embedding) for each and every sentence
- We will be using cosine similarity to find similarity between sentences. Similarities between sentence vectors are then calculated and stored in a matrix.
- The similarity matrix is then converted into a graph, with sentences as vertices and similarity scores as edges, for sentence rank calculation.
- Finally, we will pink n sentences from the final summary
4. Abstraction-based approach
This method will build a neural network to truly workout the relation between the input and the output , not merely copying words. Abstractive summarization is what you might do when explaining a book you read to your friend, and it is much more difficult for a computer to do than extractive summarization. Computers just aren’t that great at the act of creation. To date, there aren’t any abstractive summarization techniques which work suitably well on long documents.
- Pros: You can use words that were not in the original input. It enables to make more fluent and natural summaries.
- Cons: But it also a much harder problem as you now require the model to generate coherent phrases and connectors.
4.1. Encoder-Decoder Sequence to Sequence Model
The encoder-decoder model is composed of encoder and decoder like its name. The encoder converts an input document to a latent representation (vector), and the decoder generates a summary by using it.
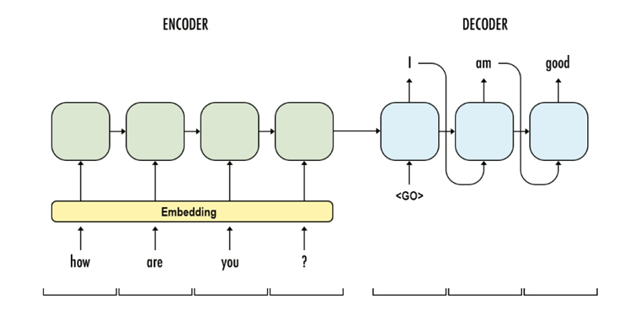
Nowadays, the encoder-decoder model that is one of the neural network models is mainly used in machine translation. So this model is also widely used in abstractive summarization model.
Encoder:
- A stack of several recurrent units (LSTM or GRU cells for better performance) where each accepts a single element of the input sequence, collects information for that element and propagates it forward.
- In question-answering problem, the input sequence is a collection of all words from the question. Each word is represented as xiwhere i is the order of that word.
- The hidden states hi are computed using the formula:
This simple formula represents the result of an ordinary recurrent neural network. As you can see, we just apply the appropriate weights to the previous hidden state and the input vector .
Encoder Vector
- This is the final hidden state produced from the encoder part of the model. It is calculated using the formula above.
- This vector aims to encapsulate the information for all input elements in order to help the decoder make accurate predictions.
- It acts as the initial hidden state of the decoder part of the model.
Decoder:
- A stack of several recurrent units where each predicts an output at a time step t.
- Each recurrent unit accepts a hidden state from the previous unit and produces and output as well as its own hidden state.
- In question-answering problem, the output sequence is a collection of all words from the answer. Each word is represented as where i is the order of that word.
- Any hidden state iscomputed using the formula:
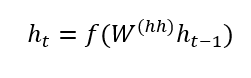
As you can see, we are just using the previous hidden state to compute the next one.
- The output at time step t is computed using the formula:
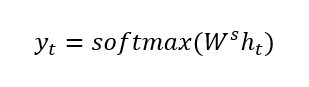
We calculate the outputs using the hidden state at the current time step together with the respective weight W(S). Softmax is used to create a probability vector which will help us determine the final output.
5. Conclusion
To calculate the accuracy of Text Summarization, we usually ROUGE score. ROUGE stands for Recall-Oriented Understudy. It is essentially of a set of metrics for evaluating automatic summarization of texts as well as machine translation. It works by comparing an automatically produced summary or translation against a set of reference summaries.
For more information on AIs and its impacts on our future, visit:
https://blog.fpt-software.com/a-few-thoughts-on-ais-and-its-impacts-on-our-future



